由于前程无忧上岗位投递记录只保留两个月,想记录下。
由于之前写过一个爬工作岗位的爬虫,所以这次我就拿之前的代码,改了下,发现爬不到东西。一番折腾后,发现。爬虫下载网页,获取登陆是不会记住你浏览器的登陆状态的,就相当于,在一个新的,从未登陆过该网站的浏览器上下载页面,而我需要的页面是登陆后的页面。
程序代码放在Github
对于怎么获取登陆后的页面,有两种思路
使用账号,密码登陆,如果该网站登陆系统简单的话,没有验证码啥的,有验证码的话,可以使用图形识别库
使用cookie绕过登陆页面
cookie:
Cookie(复数形态Cookies),中文名称为“小型文本文件”或“小甜饼”[1],指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。定义于RFC2109。是网景公司的前雇员卢·蒙特利在1993年3月的发明[2]。
因为HTTP协议是无状态的,即服务器不知道用户上一次做了什么,这严重阻碍了交互式Web应用程序的实现。在典型的网上购物场景中,用户浏览了几个页面,买了一盒饼干和两瓶饮料。最后结帐时,由于HTTP的无状态性,不通过额外的手段,服务器并不知道用户到底买了什么,所以Cookie就是用来绕开HTTP的无状态性的“额外手段”之一。服务器可以设置或读取Cookies中包含信息,借此维护用户跟服务器会话中的状态。
by wikipedia
我打算写的是小工具,为了方便起见直接用使用cookie的方式。
期间遇到的坑
解析网页
在写程序的过程中,关于BeautifulSoup, requests,urlopen几个的作用有点糊涂,在这遍整理下
BeautifulSoup官方解释
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。requests文档里的解释
Requests 是 Python HTTP 库,
Requests 允许你发送的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在Requests 内部的 urllib3。
urlopen
urlopen是urllib(urllib提供了一系列用于操作URL的功能)里的一个方法,执行urlopen方法之后,返回一个response对象,返回信息便保存在这里面使用cookie绕过登陆
####cookie
可以使用抓包软件来获取cookie,mac端用charles,windows可以用fiddler,当然也可以直接用Chrome的开发者工具
1
2
3
4cookie = {key: value} # 这里写获取到的cookie,使用键值对的格式
s = requests.get(url, cookies = cookie) # 返回的是Response 对象
s.encoding='gbk' # 由于51的网页编码是gbk,转码防止乱码
page = s.text # 读取服务器响应的内容,requests获得的是requests对象我这里碰到的坑是,自己想着完美主义,想cookie设置一遍就好,换下一页时,不用在设置。我需要爬多个网页,但自己cookie只设置了第一个网页,换了下一页的网址后,使用正则获取不到我要的东西,当时很奇怪,排查了很久,后来发现是cookie设置的问题。后来我在requests文档看到会话对象,就以为这个可以解决了我的问题。就匆匆用上了,却发现还是不行,在看文档发现,人家早就在后面写了。
会话对象让你能够跨请求(请求是指get,post,delete,put等)保持某些参数。它也会在同一个 Session 实例发出的所有请求之间(不是在程序中)保持 cookie, 期间使用
urllib3的 connection pooling 功能。所以如果你向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升不过需要注意,就算使用了会话,方法级别的参数也不会被跨请求保持。下面的例子只会和第一个请求发送 cookie ,而非第二个
2
3
4
5
6
7
8
9
10
>
> r = s.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
> print(r.text)
> # '{"cookies": {"from-my": "browser"}}'
>
> r = s.get('http://httpbin.org/cookies')
> print(r.text)
> # '{"cookies": {}}'
>
后来,就直接在每个requests.get()里加一个cookie参数。纠结好久,就是为了requests.get()少写一个参数,太不值了。
CookieJar就是一个cookie文件,在其他语言中就是实现保存cookie的包。
如果想只设置一遍的话可以使用scrapy框架,里面有解决方案
requests.get()返回的是什么
1 | import requests |
headers设置
很多网站禁止了类似python的爬虫,所以需要模拟浏览器浏览,有的网站更是需要登陆才能浏览。
模拟浏览器主要是增加一个headers,在chrome浏览器上按下f12,就可以看到如下的headers信息。
假设不自己加入headers信息中的User-Agent。python代码登录时会默认使用User-Agent: Python-urllib/3.4
我们在chrome浏览器中按F12审查元素 > Network > Headers中能够看到User-Agent应该设置为:’Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36’
一般要加入的headers信息有:
1 | 'Host': '', 'Accept': '', 'User-Agent': '', 'Accept-Language': '', Accept-Encoding |
要获取的是职位,薪资,公司名,地点。网页结构如下:
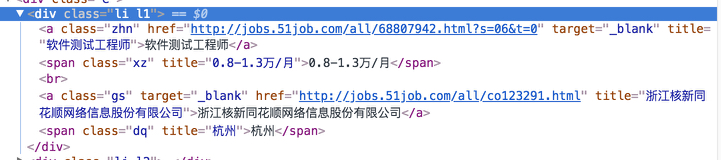
起初写的正则是
1 | reg = re.compile(r'class="li l1">.*? target="_blank" title="(.*?)"</a> <span class="xz" title="(.*?)".*? title="(.*?)".*? <span class="dq" title="(.*?)".*?</span>',re.S) |
圆括号分组匹配使得findall返回元组,元组中,几对圆括号就有几个元素,保留空匹配。
但是每次都是返回空列表。
然后删掉就可以匹配了
- 不删掉,返回的是空,还有程序运行的时间特别长,意味着程序没找到相应的字符
- 为什么会找不到
最后排查的时发现 和之间应该用东西,但是我不知道是什么,百度谷歌啥的也都搜不到,也问了伟哥,后来突然想到,既然想知道他们之间有啥东西,那为什么不直接打印出来呢?(.*?),前面的不就是使用(.*?)来打印职位等信息的啊。
既然都用到了用(.*?)打印,那为什么不打印
</a>与之间的东西惰性思维,一遇到问题就想着搜索,网上有没有现成的解决方法,却不去自动思考下,尝试去解决问题。后来想到通过打印的方法,是因为在网上找不到相应的解决方法,没办法,只能自己解决了。
打印出来发现
1 | '\r\n ' # \r\n是回车换行符 |
Unix系统里,每行结尾只有”<换行>”,即”\n”;Windows系统里面,每行结尾是”<回车><换行>”,即”\r\n”;Mac系统里,每行结尾是”<回车>”。一个直接后果是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
正则匹配错误 expected string or bytes-like object是为什么
正则是用来匹配字符串的
如果你用来匹配其它对象,如整数就会出现上述错误
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。
re.S 使 . 匹配包括换行在内的所有字符
re.M、re.MULTILINE
^和$分别匹配目标字符串中行的起始和结尾,而不是严格匹配整个字符串本身的起始 和结尾
re.S、rer.DOTALL
“.”(点号)通常匹配除了\n(换行符)之外的所有单个字符;该标记表示“.”(点号) 能够匹配全部字符
匹配包括换行符在内的任意字符,以下为正确的正则表达式匹配规则:
([\s\S]*)
同时,也可以用 “([\d\D]*)”、“([\w\W]*)” 来表示。
经验教训
碰到需要自己写程序解决问题时,可以完成任务为目的,不过过程怎么,首先得把程序写出来,至于优化,完美,效率这些问题可以在写完之后在重构,查资料完善它。不然会陷入时间黑洞,背离初衷。
其实也和自己掌握的知识比较浅,有种坐井观天的感觉,只能窥一斑但不能见全貌。知识的系统性,然后经验也很重要,多读多写。
解决问题的步骤
确定问题,我的问题是什么?
什么导致了这个问题,为什么会产生这个问题?
怎么解决问题?
自己尝试无果后,尝试在搜索引擎搜索,建议多换几个关键词,使用google,中文/英文,如果是框架,函数问题,可以查文档
询问有经验的人
一切无果后,先归档,然后问问自己有没有别的解决方案
解决后,反思是缺少知识,还是粗心考虑不周等原因,缺啥补啥。
如果知识点问题,记下笔记,防止下次遇坑。经验就是这么来的
其中要注意的点,是要给寻找答案的过程中,设立时间盒,比如规定半小时内解决,如果解决不了先放一放,不然会成为时间黑洞,时间一下子就全耗进去了